本篇主要用于盘点Java中常见的多线程知识
1.复杂的内存模型
何为Java的内存模型(JMM)? JMM实际上是为了避免C/C++在不同机器上内存适配的问题, 尝试定义程序中各个变量的访问规则, 而不是说简单的将内存划分为堆/栈.
Java内存模型规定了两种内存: 工作内存(例如对应于虚拟机栈局部变量)与主内存(对应于堆的对象实例). 线程对变量的所有操作都必须在工作内存中进行, 而不能读写主内存中的变量.
(以下内容摘自深入理解JVM虚拟机) 关于主内存与工作内存之间的交互协议, 即一个变量如何从主内存拷贝到工作内存. 如何从工作内存同步到主内存中的实现细节. java内存模型定义了8种操作来完成, 这8种操作每一种都是原子操作. 8种操作如下:
i. lock(锁定):作用于主内存, 它把一个变量标记为一条线程独占状态.
ii .unlock(解锁):作用于主内存, 它将一个处于锁定状态的变量释放出来,释放后的变量才能够被其他线程锁定.
iii. read(读取):作用于主内存, 它把变量值从主内存传送到线程的工作内存中,以便随后的load动作使用.
iv. load(载入):作用于工作内存, 它把read操作的值放入工作内存中的变量副本中.
v. use(使用):作用于工作内存, 它把工作内存中的值传递给执行引擎,每当虚拟机遇到一个需要使用这个变量的指令时候,将会执行这个动作.
vi. assign(赋值):作用于工作内存, 它把从执行引擎获取的值赋值给工作内存中的变量,每当虚拟机遇到一个给变量赋值的指令时候,执行该操作.
vii. store(存储):作用于工作内存, 它把工作内存中的一个变量传送给主内存中,以备随后的write操作使用.
vii. write(写入):作用于主内存, 它把store传送值放到主内存中的变量中.
并且必须满足如下规则:
i. 不允许read和load、store和write操作之一单独出现, 以上两个操作必须按顺序执行, 但没有保证必须连续执行, 也就是说, read与load之间, store与write之间是可插入其他指令的.
ii. 不允许一个线程丢弃它的最近的assign操作, 即变量在工作内存中改变了之后必须把该变化同步回主内存.
iii. 不允许一个线程无原因地(没有发生过任何assign操作)把数据从线程的工作内存同步回主内存中.
iv. 一个新的变量只能从主内存中“诞生”, 不允许在工作内存中直接使用一个未被初始化(load或assign)的变量, 换句话说就是对一个变量实施use和store操作之前, 必须先执行过了assign和load操作.
v. 一个变量在同一个时刻只允许一条线程对其执行lock操作, 但lock操作可以被同一个条线程重复执行多次, 多次执行lock后, 只有执行相同次数的unlock操作, 变量才会被解锁.
vi. 如果对一个变量执行lock操作, 将会清空工作内存中此变量的值, 在执行引擎使用这个变量前, 需要重新执行load或assign操作初始化变量的值.
vii. 如果一个变量实现没有被lock操作锁定, 则不允许对它执行unlock操作, 也不允许去unlock一个被其他线程锁定的变量.
viii. 对一个变量执行unlock操作之前, 必须先把此变量同步回主内存(执行store和write操作).
听起来很复杂, 实际上只用两张图就能解释:
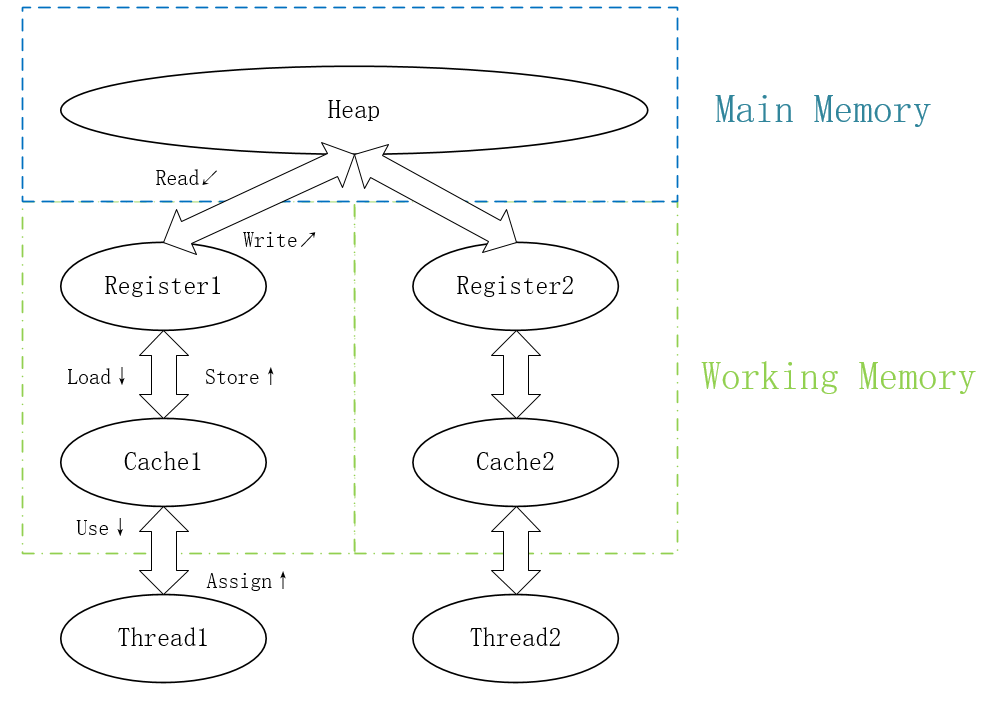
前四条操作是指, 每一个系列操作必须完整从下到上每一步都执行(不能丢弃assign操作, 不能不进行assign操作就直接进行store/write, 不能拆分store/write), 或者从上到下每一步都执行(use操作除外).
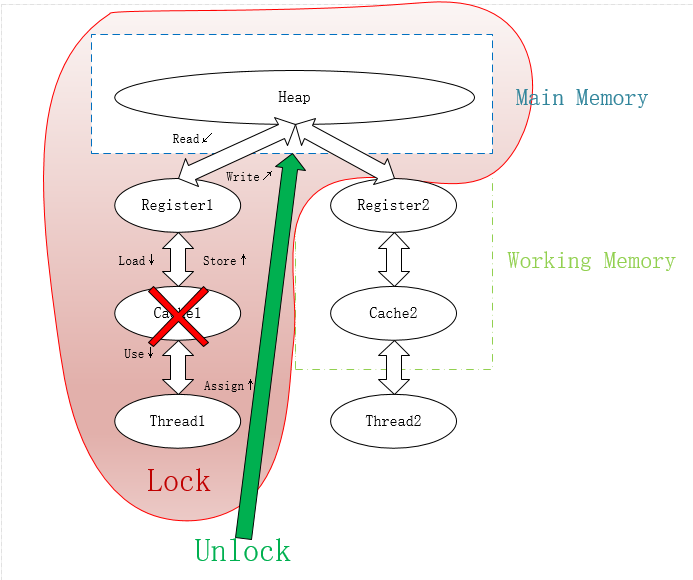
后面的锁操作很好理解, 需要注意的是, 执行lock需要清空工作内存中的值. 执行unlock需要将变量同步回主内存.
在之前的介绍里, 已经简单讲解了volatile关键字的可见性和有序性. 实现这两个特性只需要额外保证上下之间的三级操作的为一个整体, 中间不能插入其他操作即可.
long, double 是64位操作, 拥有非原子性协定. 大部分虚拟机执行的都是原子性操作.
2. 绕不过去的线程
从JVM层面而言, 实现线程主要有3种方式, 使用内核线程实现, 使用用户线程实现和使用用户线程与轻量级进程混合实现.
内核线程(Kernel-Level Thread)是直接由操作系统内核支持的线程, 内核线程可以认为是内核的一个分身.
轻量级进程(Light Weight Process, LWP), 通常意义上的线程即为轻量级进程, 轻量级进程与内核线程有一一对应的关系. 轻量级进程由内核实现, 创建(initiation), 析构(deconstruct), 同步(synchronization) 都需要系统调用. 系统调用需要在用户态(User Mode)与内核态(Kernel Mode)来回切换. 轻量级进程需要消耗内核资源.
用户线程(User Thread), 用户线程完全建立在用户空间的线程库上, 系统内核无法感知线程的实现, 系统也可以不切换到内核态, 前提是创建, 切换, 调度都是需要自行考虑的问题.
JVM中并没有规定Java线程是如何实现, 操作系统对线程模型的支持很大程度上决定了Java实际的线程模型. 在Windows和Linux中, 一条Java线程映射了一条轻量级进程,
线程调度分为两种: 协同式线程调度(Cooperative Threads-Scheduling), 抢占式线程调度(Preemtive Threads-Scheduling). “协程”即是协同式调度的实现, 线程要把自己的事情做完后才会进行线程切换. 优点是不存在线程同步的问题, 但如果某线程出现了问题而且不切换, 程序会被阻塞. 抢占式调度中每个线程由系统来分配执行时间.
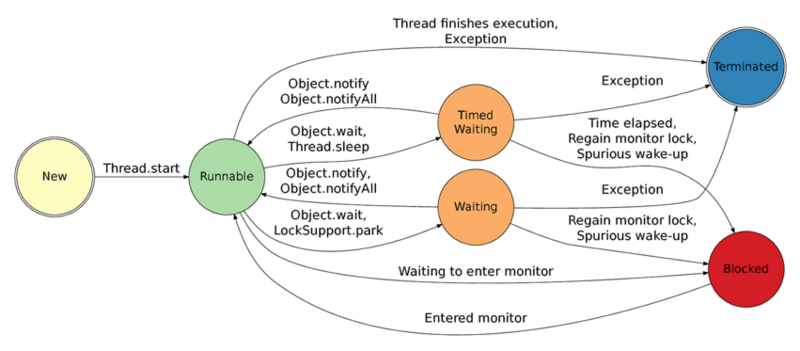
线程的6种状态
3.ThreadLocal
ThreadLocal可以理解为线程的局部变量(Local Variable), 这些变量在多线程环境下访问可以保证各个线程里的变量相互独立. 这些变量一般被设为private static.
This class provides thread-local variables. These variables differ from their normal counterparts in that each thread that accesses one (via its {@code get} or {@code set} method) has its own, independently initialized copy of the variable. {@code ThreadLocal} instances are typically private static fields in classes that wish to associate state with a thread (e.g., a user ID or Transaction ID.
例如每一个汽修工人代表了一个独立的线程, 每个汽修工人都有一个螺丝刀代表一个线程的局部变量, 在所有需要上螺丝的时候(线程的多个函数)都需要这个螺丝刀. ThreadLocal相当于实现了一个维护螺丝刀用的螺丝刀盒子, 每一个螺丝刀上会有工人的工号标签(线程id标识), 工人按照其自己的工号取螺丝刀. ThreadLocal是所有线程共享, 减少了同一个线程内多个函数或者组件公共变量传递的复杂度.
ThreadLocal利用了Map的方法存储局部变量, 线程的id作为唯一key值, 例如下面的源码:




ThreadLocal的get()方法是通过当前线程获取当前线程的ThreadLocalMap, 即每一个线程都有一个成员变量ThreadLocalMap, 利用ThreadLocal的this指针作为key值获取线程拥有的ThreadLocalMap中的Value值. 并且使用开放地址法(Open-Address)解决冲突.
值得注意的是, ThreadLocalMap的Key值ThreadLocal为弱引用, 在下次full GC中会被无条件清理. 但是这个操作不会造成内存泄漏 (因为被置为null无法访问到key). 原因是在get/remove时, 如果第一次计算hash, 根据下标获取没有获取到对应key的元素, 按照开放地址查找的方法, 会删除表中所有访问到的key为null的结点.
4.Interrupt
Java 提供了线程中断机制. 线程检查其是否被中断了, 然后决定是否相应该响应. 线程可以忽略中断请求. 和此线程的函数有4个, 分别是:
public void interupt()
public boolean isInterrupted()
publc static boolean interrupted()
private native boolean isInterrupted(boolean flag)
interrupt()调用提供了线程的中断方法, isInterrupted()实际上是isInterrupted(false), interrupted实际上是currentThread().isInterrupted(true). isInterrupted(boolean)是一个静态native方法. 区别在于isInterrupted() 不会改变线程的中断状态, 而且提供非当前线程的调用. interrupted() 是当前线程的判断, 会改变reset线程中断状态, 并且是private调用. 推荐使用isInterrupted()