本篇主要总结集合框架/Hashmap相关的内容
介绍之前先记住这张图
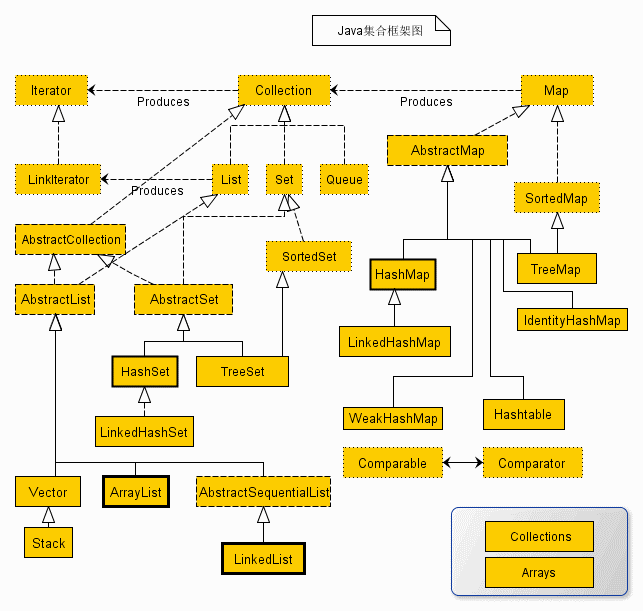
虚线(点/短线)分别表示了 Interface/Abstract class, 实线表示了 Class, 箭头表示了实现或者继承.
1.Collection
最基本的集合接口, 实现了一些基础方法, 例如 size(), isEmpty(), add(), remove(), contains(), clear() 等等.
Collection 有三个子接口: List, Set, Queue.
List下有AbstractList接口, Vector, Stack, ArrayList, LinkedList都实现了该接口.(LinkedList还实现了Deque/Queue接口)
Set下有SortedSet和AbstractSet虚类, HashSet实现了AbstractSet虚类, TreeSet二者都实现了. (HashSet 是用HashMap实现)
2. TreeSet/TreeMap
TreeSet/TreeMap可以看作 HashSet和HashMap的排序版本, 例如TreeSet可以使用迭代器迭代输出排序之后的Set. (Set中的类型需要支持Comparable接口.) TreeMap则可以实现HashMap的排序. 其具体实现是红黑树.
简单介绍一下红黑树, 满足以下几个性质的二叉搜索树即为红黑树:
i. 节点是红色或者是黑色
ii. 根节点是黑色
iii. 叶子(Nil)结点是黑色
iv. 红色节点的子节点都是黑色
v. 从任何一个结点向下出发的所有路径都应该包含数量相等的黑色节点
由于任何一条路径最后的两个结点为红->Nil(黑)或者黑->Nil(黑), 而且由于红色节点的子节点为黑色节点, 且所有路径黑色结点数量一致, 所以任何两条路径长度差不会大于一倍. 即从根到叶子的最长的可能路径不多于最短的可能路径的两倍长, 也就保证了在最坏的情况下依然有比较好的时间表现. (最坏情况是, 最短的可能路径都是黑色节点,最长的可能路径有交替的红色和黑色节点.)

红黑树
插入和删除较为复杂, 但是依然可以把时间复杂度控制在O(logn)内.
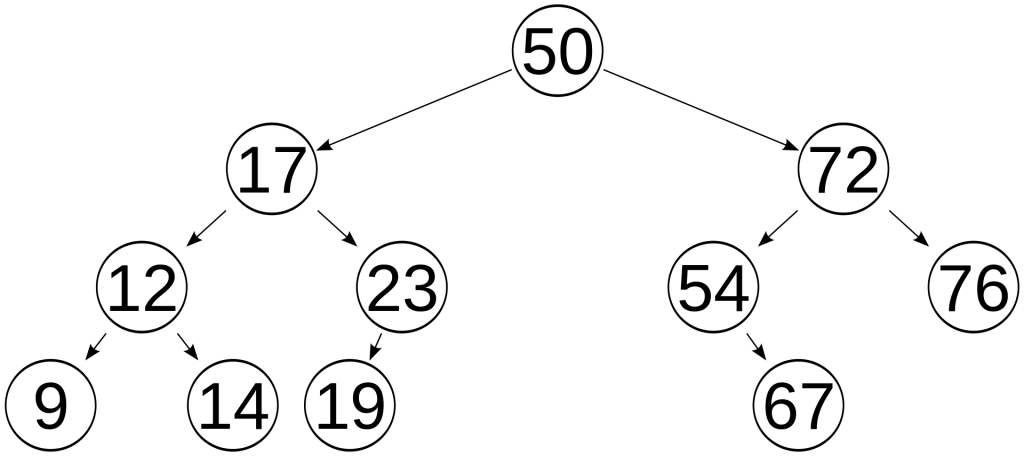
提到了红黑树, 顺便提一下AVL树, B+树, Trie树
AVL树(Adelson-Velsky and Landis): 在AVL树中任何节点的两个子树的高度最大差别为1, 所以它也被称为高度平衡树. 维护该树成本较高, 在windows对进程地址空间的管理用到了AVL树.
AVL树
B+树: 如果此B+树的序数(order)是m , 则除了根之外的每个节点都包含最少 \( {\displaystyle \lfloor m/2\rfloor } \) 个元素, 最多 m-1 个元素,对于任意的节点有最多m个子指针. 通常用于数据库和操作系统的文件(索引)系统中. B+ 树的特点是能够保持数据稳定有序, 其插入与修改拥有较稳定的对数时间复杂度.
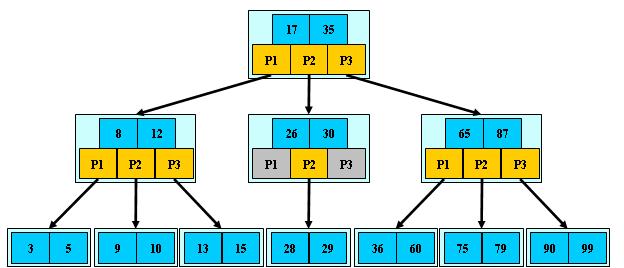
B+树
为什么采用B+树作为数据库索引呢?是因为数据库的读写发生在磁盘, 与内存中Random Access方式不同, 磁盘被划分成了很多片, 每一片有很多扇区与磁道. 不同片或者扇区/磁道需要磁头进行物理移动. 所以磁盘一般适合顺序读取. 以SQL数据库为例, 设计者将一个结点设计为一个页, 由于磁盘每次都是按页读取, 所以只需要一次IO, 即可读出一个结点. 然后将根节点放在主存中, 如果B+树的序数为h, 那么最多只需要h-1次IO. 其渐进复杂度为O(h)=O(logN/logd), d一般是一个比较大的数字, 所以h会非常小.
Trie 树可以看作一个确定有限状态自动机, 一般用于搜索提示框的字符匹配.
3.到处使用的HashMap
有关HashMap的大致原理此处不多介绍. 着重介绍以下几个概念:
桶, 用于存放Value的数组, 在源码中即为申明为Nodes的内部类, 实现了Map.Entry<K,V>的接口. 拥有四个变量hash, key, value, next. next说明是开链法解决冲突.
hash()函数, 用于计算哈希值的函数. 利用key的hashcode高16位与低16位异或取模得到的结果. hashcode()是一个native方法, 具体由虚拟机底层实现(不是内存地址). 模值是桶的大小, 一般是16的整数倍. 一般而言, 为了避免冲突, 模值取素数, 但是java1.8 在取模/扩容运算与冲突之间Tradeoff的结果是, 将初始桶值取为16. (Hashtable则是11.)
装载因子loadfactor, 默认0.75, 是大量实践的结果. 当Hashmap的大小超过0.75n时, 便会发生扩容. Java1.8 中, 扩容操作只需要看哈希值多模一位的结果(例如原来模16, 现在模32), 如果高位多了1个1, 则移到移位后的位置, 否则保持原位置不变. 如此操作省去很多时间代价. (Jdk1.7是全部重新计算)
链, 当链的长度超过8时, Java1.8中使用了实现了LinkedHashMap.Entry<K, V>的TreeNode, LinkedHashMap是由红黑树实现, 所以TreeNode本身也是红黑树.(如上面所讲). 当不超过8时, 使用正常的链表(Node中的next关键字).
线程安全性, 众所周知HashMap是线程不安全的, 原因在于多个线程可能同时对一个Nodes进行操作, 导致读写不一致甚至发生死循环. 例如在多线程同时添加元素, 同时invoke resize()的过程中, 线程1将原来占位下标3的Nodes移动到了扩容后的6, 此时如果线程2误以为原来的下标3未移动, 将next也标记为扩容后的6, 实际上导致扩容后的6的next还是其本身, 导致发生死循环.
4.ConcurrentHashMap
为了解决线程安全问题, 可以使用HashTable(Since Java1.2), 但是由于HashTable过于Old-fashion, 而且对整个Map加锁会导致性能急剧恶化, 所以一般采用ConcurrentHashMap (extends AbstractMap)进行并发操作.
在jdk1.7以及以前的版本, ConcurrentHashMap主要通过对内部的桶进行分割(Segment), Segment实现了 ReentrantLock, 即每一个Segment实现了一个锁. 其逻辑结构如下:
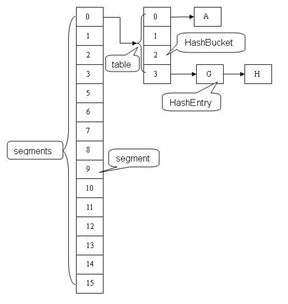
ConcurrentHashMap 的Key, hash成员由final修饰, 为immutable类型, 保证了这两个成员不会被修改. value, next成员由volatile修饰, 保证读取操作是实时同步的. put和get操作需要计算两次hash, 以确定具体存在的Segment与Bucket. put需要进行lock()操作, get()则不需要进行.
ConcurrentHashMap的size()操作会对所有的Segment不加锁统计三次, 如果存在相邻的两次统计结果一致, 而且没有发生更新, 则认为此时间段内Segment没有发生变化. 如果超过三次, 则会对所有的Segment加锁, 然后进行统计.
Hash函数, 由于ConcurrentHashMap的设计理念在于分段, 所以hash()应当尽量减小碰撞, 用于提高Segment的效率. 所以和HashMap中时间与空间Tradeoff的哈希函数有很大区别.
在jdk1.8的版本, ConcurrentHashMap不再有Segments的概念, 而是定义了三个原子操作:
i. 获取桶上位置i的节点
ii. 使用CAS方法设置位置i上的结点
iii. 使用volatile方法设置结点上的值
在扩容时, 如果线程一已经处理过某节点, 该结点会被标记为MOVED, 即forwardingNode, 则直接跳过. 如果没有标记, 则使用synchronized关键字对结点进行上锁处理. 在put()时也是类似的
总的来说, jdk1.8减小了原子粒度(也增加了代码行数, 1000->6000), 从原来的Segment变成了Nodes, 同时利用三个CAS(Compare and Swap) 操作保证了对Nodes操作前的原子性. 由于jdk1.8 对synchronized关键字的优化, 使得ReentrantLock对synchronized 关键字的优势不再明显.
5.WeakHashMap
在介绍WeakHashMap之前, 需要介绍引用的4种类型:
Strong Reference / Soft Reference / Weak Reference / Phantom Reference 四种引用强度依次逐渐减弱.
Strong Reference 只要还存在, 就永远不会被回收.
Soft Reference 在将要发生内存溢出时, 会尝试被回收
Weak Reference 在下一次GC时就会被回收
Phantom Reference 在回收时会得到一个系统通知.
WeakHashMap 的Entry (即结点)是WeakReference 的子类. 其key值为弱引用key值, 允许为null, 如果key被置为null, 则会被替换为一个final static 的原始Object: NULL_OBJECT. WeakHashMap 维护了一个ReferenceQueue<K> queue. 每当对应的K类型的对象失效(被回收), JVM会将该对象加入queue中(代码中并看不到queue的入队过程) . 在 expungeStaleEntries() 函数中, 遍历加入到queue中的对象, 并且从WeakHashMap中删除. 而expungeStatbleEntries() 会在resize(), getTable(), size() 等函数中调用, 又由于put(), get() 等操作需要getTable(), isEmpty需要得到size(), 所以这些操作也会使WeakHashMap删除被回收的弱Key值. (值得注意的是, jdk1.8中, 删除key的操作对queue加了synchronized 关键字, 还有unchecked 的annotation, 可能是在调用上述函数的时候可能会发生gc, 在删除queue之前将queue的内容改变.)
总的来说, WeakHashMap可以用作比较大的HashMap的内存缓存的作用, 主动将置为Null的key进行回收, 这样WeakHashMap就不会占用过多的内存空间.
例如:
WeakHashMap map = new WeakHashMap<>();
Integer[] arr = new Integer[20];
for(int i = 0; i < 20; i ++) {
arr[i] = new Integer(i);
map.put(arr[i], arr[i].toString());
System.out.println(map.get(arr[i]));
}
for(int i = 0; i < 20; i ++){
arr[i] = null;
}
System.gc();
try {
Thread.sleep(3000);
}catch (Exception e){
e.printStackTrace();
}finally {
System.out.println(map.isEmpty());
}
HashMap最后会输出false, WeakHashMap最后则会输出true.
6.LinkedHashMap
LinkedHashMap可以看作是双向循环链表(也是双端队列)版本的HashMap, 对键值对插入与删除的操作, 大致逻辑结构如下图:
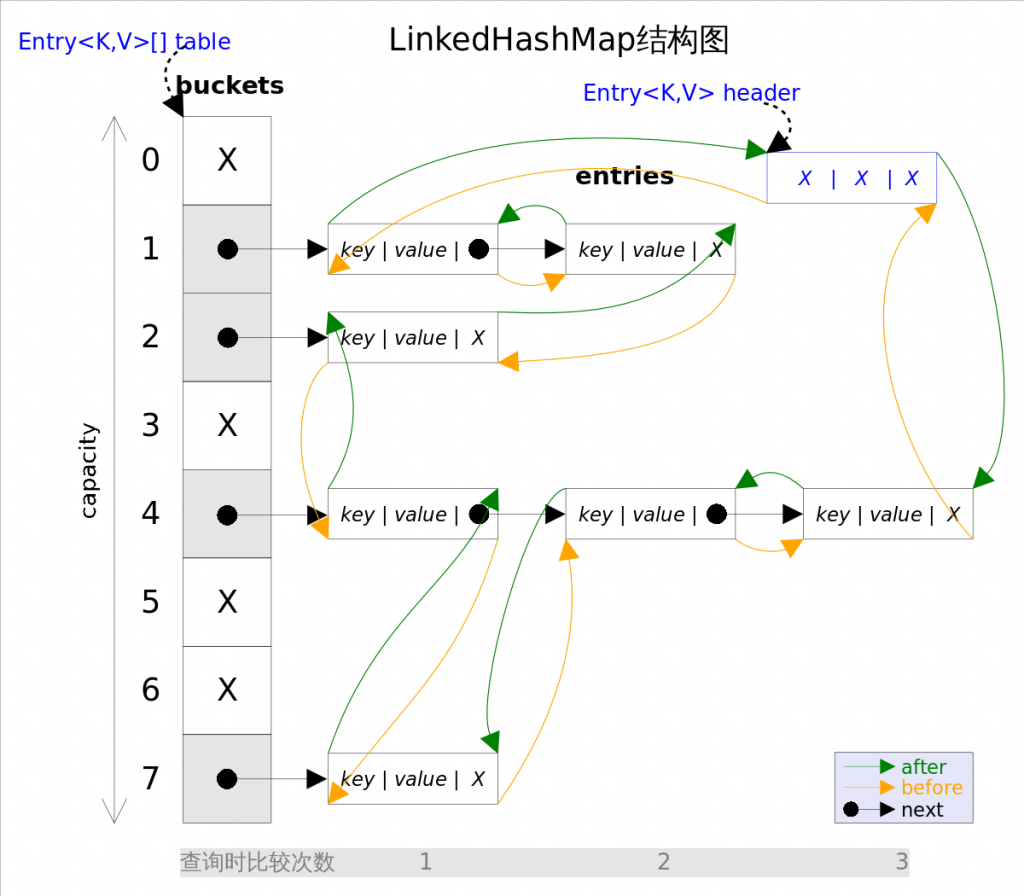
当LinkedHashMap需要插入元素时, 有两个操作:
i. 计算Hash值, 放入相应的Bucket中, 如果发生冲突, 采用拉链法挂在冲突位置后面
ii. 在双向循环链表的尾结点插入该节点.
而且访问 LinkedHashMap 的每一个结点也会将元素插入双向循环链表的尾节点.
双向循环链表维护了一个boolean的accessOrder的值(构造时确定), 用于标记按访问顺序排列(true)或者按插入顺序(false)排列. LinkedHashMap 也可以用作大的HashMap缓存, 这也就支持了 LRU(Least Recently Used) 算法.
例如:
public class LRUCache extends LinkedHashMap
{
public LRUCache(int maxSize)
{
super(maxSize, 0.75F, true);
maxElements = maxSize;
}
protected boolean removeEldestEntry(java.util.Map.Entry eldest)
{
return size() > maxElements;
}
private static final long serialVersionUID = 1L;
protected int maxElements;
}
7.Arrays/Collections
Arrays/Collections 提供了为数组和Collection进行操作的工具类, 比如sort()方法. (Collection对其迭代器进行sort)
Collections类还提供了synchronizedMap, synchronizedList 等线程同步的类, 并且使用单例模式的静态工厂构造方法进行构造. 即将SynchronizedMap申明为私有静态域, 使用静态工厂方法获得该实例. SynchronizedMap 拥有一个标记为final的mutex Object, 每次put(), get等操作执行前, 需要先获取mutex的锁, 才能执行相应的操作.
本篇主要总结集合框架/Hashmap相关的内容
介绍之前先记住这张图
虚线(点/短线)分别表示了 Interface/Abstract class, 实线表示了 Class, 箭头表示了实现或者继承.
1.Collection
最基本的集合接口, 实现了一些基础方法, 例如 size(), isEmpty(), add(), remove(), contains(), clear() 等等.
Collection 有三个子接口: List, Set, Queue.
List下有AbstractList接口, Vector, Stack, ArrayList, LinkedList都实现了该接口.(LinkedList还实现了Deque/Queue接口)
Set下有SortedSet和AbstractSet虚类, HashSet实现了AbstractSet虚类, TreeSet二者都实现了. (HashSet 是用HashMap实现)
2. TreeSet/TreeMap
TreeSet/TreeMap可以看作 HashSet和HashMap的排序版本, 例如TreeSet可以使用迭代器迭代输出排序之后的Set. (Set中的类型需要支持Comparable接口.) TreeMap则可以实现HashMap的排序. 其具体实现是红黑树.
简单介绍一下红黑树, 满足以下几个性质的二叉搜索树即为红黑树:
i. 节点是红色或者是黑色
ii. 根节点是黑色
iii. 叶子(Nil)结点是黑色
iv. 红色节点的子节点都是黑色
v. 从任何一个结点向下出发的所有路径都应该包含数量相等的黑色节点
由于任何一条路径最后的两个结点为红->Nil(黑)或者黑->Nil(黑), 而且由于红色节点的子节点为黑色节点, 且所有路径黑色结点数量一致, 所以任何两条路径长度差不会大于一倍. 即从根到叶子的最长的可能路径不多于最短的可能路径的两倍长, 也就保证了在最坏的情况下依然有比较好的时间表现. (最坏情况是, 最短的可能路径都是黑色节点,最长的可能路径有交替的红色和黑色节点.)
红黑树
插入和删除较为复杂, 但是依然可以把时间复杂度控制在O(logn)内.
提到了红黑树, 顺便提一下 AVL 树, B+ 树, Trie 树
AVL树(Adelson-Velsky and Landis): 在 AVL 树中任何节点的两个子树的高度最大差别为1, 所以它也被称为高度平衡树. 维护该树成本较高, 在windows对进程地址空间的管理用到了 AVL 树.
AVL树
B+ 树: 如果此 B+ 树的序数 (order) 是 \(m\) , 则除了根之外的每个节点都包含最少 \( {\displaystyle \lfloor m/2\rfloor } \) 个元素, 最多 \(m-1\) 个元素,对于任意的节点有最多 \(m\) 个子指针. 通常用于数据库和操作系统的文件(索引)系统中. B+ 树的特点是能够保持数据稳定有序, 其插入与修改拥有较稳定的对数时间复杂度.
B+ 树
为什么采用 B+ 树作为数据库索引呢?是因为数据库的读写发生在磁盘, 与内存中Random Access方式不同, 磁盘被划分成了很多片, 每一片有很多扇区与磁道. 不同片或者扇区/磁道需要磁头进行物理移动. 所以磁盘一般适合顺序读取. 以 SQL 数据库为例, 设计者将一个结点设计为一个页, 由于磁盘每次都是按页读取, 所以只需要一次 IO, 即可读出一个结点. 然后将根节点放在主存中, 如果 B+ 树的序数为h, 那么最多只需要 h-1 次 IO. 其渐进复杂度为O(h)=O(logN/logd), d 一般是一个比较大的数字, 所以 h 会非常小.
Trie 树可以看作一个确定有限状态自动机, 一般用于搜索提示框的字符匹配.
3.到处使用的 HashMap
有关 HashMap 的大致原理此处不多介绍. 着重介绍以下几个概念:
桶, 用于存放 Value 的数组, 在源码中即为申明为 Nodes 的内部类, 实现了 Map.Entry<K,V> 的接口. 拥有四个变量 hash, key, value, next. next 说明是开链法解决冲突.
hash()函数, 用于计算哈希值的函数. 利用 key 的 hashcode 高 16 位与低 16 位异或取模得到的结果. hashcode() 是一个 native 方法, 具体由虚拟机底层实现(不是内存地址). 模值是桶的大小, 一般是16的整数倍. 一般而言, 为了避免冲突, 模值取素数, 但是 java1.8 在取模/扩容运算与冲突之间 Tradeoff 的结果是, 将初始桶值取为 16. (Hashtable则是11.)
装载因子 loadfactor, 默认 0.75, 是大量实践的结果. 当 Hashmap 的大小超过 0.75n 时, 便会发生扩容. Java1.8 中, 扩容操作只需要看哈希值多模一位的结果(例如原来模 16, 现在模 32), 如果高位多了 1 个 1, 则移到移位后的位置, 否则保持原位置不变. 如此操作省去很多时间代价. (Jdk1.7是全部重新计算)
链, 当链的长度超过8时, Java1.8 中使用了实现了 LinkedHashMap.Entry<K, V>的TreeNode, LinkedHashMap 是由红黑树实现, 所以TreeNode 本身也是红黑树.(如上面所讲). 当不超过8时, 使用正常的链表(Node中的next关键字).
线程安全性, 众所周知 HashMap 是线程不安全的, 原因在于多个线程可能同时对一个 Nodes 进行操作, 导致读写不一致甚至发生死循环. 例如在多线程同时添加元素, 同时 invoke resize() 的过程中, 线程 1 将原来占位下标 3 的 Nodes 移动到了扩容后的6, 此时如果线程 2 误以为原来的下标 3 未移动, 将 next 也标记为扩容后的 6, 实际上导致扩容后的 6 的 next 还是其本身, 导致发生死循环.
4.ConcurrentHashMap
为了解决线程安全问题, 可以使用 HashTable(Since Java1.2), 但是由于 HashTable 过于 Old-fashion, 而且对整个 Map 加锁会导致性能急剧恶化, 所以一般采用 ConcurrentHashMap (extends AbstractMap) 进行并发操作.
在jdk1.7以及以前的版本, ConcurrentHashMap主要通过对内部的桶进行分割(Segment), Segment实现了 ReentrantLock, 即每一个Segment实现了一个锁. 其逻辑结构如下:
ConcurrentHashMap 的Key, hash成员由final修饰, 为immutable类型, 保证了这两个成员不会被修改. value, next成员由volatile修饰, 保证读取操作是实时同步的. put和get操作需要计算两次hash, 以确定具体存在的Segment与Bucket. put需要进行lock()操作, get()则不需要进行.
ConcurrentHashMap的size()操作会对所有的Segment不加锁统计三次, 如果存在相邻的两次统计结果一致, 而且没有发生更新, 则认为此时间段内Segment没有发生变化. 如果超过三次, 则会对所有的Segment加锁, 然后进行统计.
Hash函数, 由于ConcurrentHashMap的设计理念在于分段, 所以hash()应当尽量减小碰撞, 用于提高Segment的效率. 所以和HashMap中时间与空间Tradeoff的哈希函数有很大区别.
在jdk1.8的版本, ConcurrentHashMap不再有Segments的概念, 而是定义了三个原子操作:
i. 获取桶上位置i的节点
ii. 使用CAS方法设置位置i上的结点
iii. 使用volatile方法设置结点上的值
在扩容时, 如果线程一已经处理过某节点, 该结点会被标记为MOVED, 即forwardingNode, 则直接跳过. 如果没有标记, 则使用synchronized关键字对结点进行上锁处理. 在put()时也是类似的
总的来说, jdk1.8减小了原子粒度(也增加了代码行数, 1000->6000), 从原来的Segment变成了Nodes, 同时利用三个CAS(Compare and Swap) 操作保证了对Nodes操作前的原子性. 由于jdk1.8 对synchronized关键字的优化, 使得ReentrantLock对synchronized 关键字的优势不再明显.
5.WeakHashMap
在介绍WeakHashMap之前, 需要介绍引用的4种类型:
Strong Reference / Soft Reference / Weak Reference / Phantom Reference 四种引用强度依次逐渐减弱.
Strong Reference 只要还存在, 就永远不会被回收.
Soft Reference 在将要发生内存溢出时, 会尝试被回收
Weak Reference 在下一次GC时就会被回收
Phantom Reference 在回收时会得到一个系统通知.
WeakHashMap 的Entry (即结点)是WeakReference 的子类. 其key值为弱引用key值, 允许为null, 如果key被置为null, 则会被替换为一个final static 的原始Object: NULL_OBJECT. WeakHashMap 维护了一个ReferenceQueue<K> queue. 每当对应的K类型的对象失效(被回收), JVM会将该对象加入queue中(代码中并看不到queue的入队过程) . 在 expungeStaleEntries() 函数中, 遍历加入到queue中的对象, 并且从WeakHashMap中删除. 而expungeStatbleEntries() 会在resize(), getTable(), size() 等函数中调用, 又由于put(), get() 等操作需要getTable(), isEmpty需要得到size(), 所以这些操作也会使WeakHashMap删除被回收的弱Key值. (值得注意的是, jdk1.8中, 删除key的操作对queue加了synchronized 关键字, 还有unchecked 的annotation, 可能是在调用上述函数的时候可能会发生gc, 在删除queue之前将queue的内容改变.)
总的来说, WeakHashMap可以用作比较大的HashMap的内存缓存的作用, 主动将置为Null的key进行回收, 这样WeakHashMap就不会占用过多的内存空间.
例如:
WeakHashMap map = new WeakHashMap<>();
Integer[] arr = new Integer[20];
for(int i = 0; i < 20; i ++) {
arr[i] = new Integer(i);
map.put(arr[i], arr[i].toString());
System.out.println(map.get(arr[i]));
}
for(int i = 0; i < 20; i ++){
arr[i] = null;
}
System.gc();
try {
Thread.sleep(3000);
}catch (Exception e){
e.printStackTrace();
}finally {
System.out.println(map.isEmpty());
}
HashMap最后会输出false, WeakHashMap最后则会输出true.
6.LinkedHashMap
LinkedHashMap可以看作是双向循环链表(也是双端队列)版本的HashMap, 对键值对插入与删除的操作, 大致逻辑结构如下图:
当LinkedHashMap需要插入元素时, 有两个操作:
i. 计算Hash值, 放入相应的Bucket中, 如果发生冲突, 采用拉链法挂在冲突位置后面
ii. 在双向循环链表的尾结点插入该节点.
而且访问 LinkedHashMap 的每一个结点也会将元素插入双向循环链表的尾节点.
双向循环链表维护了一个boolean的accessOrder的值(构造时确定), 用于标记按访问顺序排列(true)或者按插入顺序(false)排列. LinkedHashMap 也可以用作大的HashMap缓存, 这也就支持了 LRU(Least Recently Used) 算法.
例如:
public class LRUCache extends LinkedHashMap
{
public LRUCache(int maxSize)
{
super(maxSize, 0.75F, true);
maxElements = maxSize;
}
protected boolean removeEldestEntry(java.util.Map.Entry eldest)
{
return size() > maxElements;
}
private static final long serialVersionUID = 1L;
protected int maxElements;
}
7.Arrays/Collections
Arrays/Collections 提供了为数组和Collection进行操作的工具类, 比如sort()方法. (Collection对其迭代器进行sort)
Collections类还提供了synchronizedMap, synchronizedList 等线程同步的类, 并且使用单例模式的静态工厂构造方法进行构造. 即将SynchronizedMap申明为私有静态域, 使用静态工厂方法获得该实例. SynchronizedMap 拥有一个标记为final的mutex Object, 每次put(), get等操作执行前, 需要先获取mutex的锁, 才能执行相应的操作.
1 thought on “Collection 与 HashMap”