本篇主要继续盘点 java.util.concurrent 中的执行器与线程池
ThreadPoolExecutor的构造
大量的线程创建与销毁是一个十分消耗系统资源的操作, 通过 线程池-线程工厂-线程执行器 可以高效的使用线程资源, 线程可以被重复利用, 适合大量短线程的情景.
ThreadPoolExecutor 是线程池中非常重要的一个类. 其继承关系如下图所示
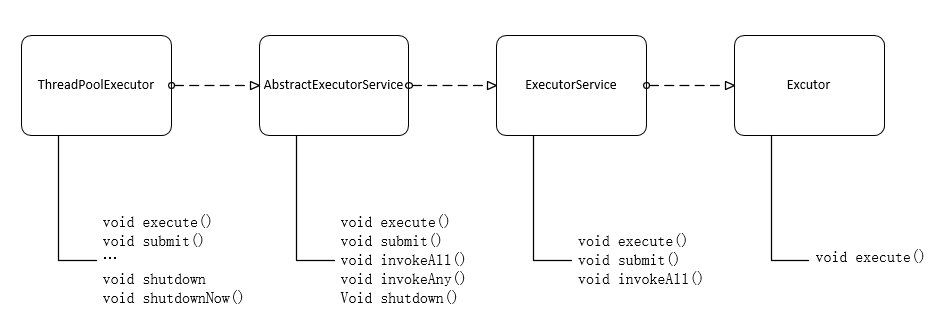
使用 TheadPoolExecutor 我们可以得到一个线程执行器,方便地执行各种大量重复的线程. ThreadPoolExecutor 有多种构造方法:
public class ThreadPoolExecutor extends AbstractExecutorService {
.....
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,RejectedExecutionHandler handler);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler);
...
}
ThreadPoolExecutor 中的成员
一个 ThreadPoolExecutor 类中有如下的重点成员:
int corePoolSize: 核心池的大小. 如果把 Executor 理解为一个工厂, 则核心池可以理解为常驻值班工人的多少.
int maximumPoolSize: 线程池最大线程数, 它表示在线程池中最多能创建多少个线程, 如果把 Executor 理解为一个工厂, 则最大线程数是允许工作的工人的多少;
long keepAliveTime: 表示线程没有任务执行时最多保持多久时间会终止. 默认情况下, 只有当线程池中的线程数大于corePoolSize时, keepAliveTime才会起作用, 直到线程池中的线程数不大于corePoolSize, 即当线程池中的线程数大于corePoolSize时, 经过特定时间将销毁过多的线程. 但是如果调用了allowCoreThreadTimeOut(boolean)方法, 在线程池中的线程数不大于corePoolSize时, keepAliveTime参数也会起作用, 直到线程池中的线程数为0;
unit: 参数keepAliveTime的时间单位, 有7种取值, 在TimeUnit类中有7种静态属性:
TimeUnit.DAYS; //天
TimeUnit.HOURS; //小时
TimeUnit.MINUTES; //分钟
TimeUnit.SECONDS; //秒
TimeUnit.MILLISECONDS; //毫秒
TimeUnit.MICROSECONDS; //微妙
TimeUnit.NANOSECONDS; //纳秒
workQueue: 一个阻塞队列, 用来存储等待执行的任务, 阻塞队列的选择后面介绍.
ThreadFactory threadFactory: 线程工厂, 主要用来创建线程;
handler: 表示当拒绝处理任务时的策略, 有以下四种取值:
i.ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常.
ii.ThreadPoolExecutor.DiscardPolicy: 也是丢弃任务, 但是不抛出异常.
iii.ThreadPoolExecutor.DiscardOldestPolicy: 丢弃队列最前面的任务, 然后重新尝试执行任务(重复此过程)
iv.ThreadPoolExecutor.CallerRunsPolicy: 由调用线程处理该任务
ThreadPoolExecutor 类中还有其他的一些比较重要成员变量:
private final ReentrantLock mainLock = new ReentrantLock(); //线程池的主要状态锁, 对线程池状态(比如线程池大小)
//runState等的改变都要使用这个锁
private volatile int poolSize; //当前的线程数
private int largestPoolSize; //用来记录线程池中曾经出现过的最大线程数
private long completedTaskCount; //用来记录已经执行完毕的任务个数
除了成员变量, 还有一些成员函数 例如 prestartAllCoreThreads() 或者 prestartCoreThread() 方法, 从这 2 个方法的名字就可以看出是预创建线程的意思, 即在没有任务到来之前就创建 corePoolSize 个线程或者一个线程. 而在默认情况下, 在创建了线程池后, 线程池中的线程数为0, 当有任务来之后, 就会创建一个线程去执行任务, 当线程池中的线程数目达到corePoolSize后, 就会把到达的任务放到缓存队列当中;
ThreadPoolExecutor的状态
与线程类似, 线程池也有以下这几种状态:
volatile int runState;
static final int RUNNING = 0;
static final int SHUTDOWN = 1;
static final int STOP = 2;
static final int TERMINATED = 3;
这几种状态的转移大致如图所示:
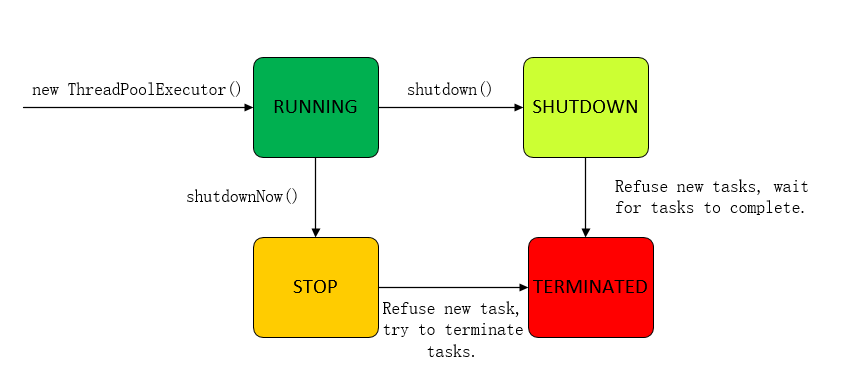
这五种状态需要三位来表示, 在状态变量AtomicInteger ctl 中高三位即为状态, 低 29位是 workers 的数量
ThreadPoolExecutor的工厂构造
ThreadPoolExecutor 一般不用构造函数进行初始化, 而是使用Executor的工厂方法进行初始化:
Executors.newScheduledThreadPool(int corePoolSize);
Executors.newFixedThreadPool(int nThreads);
Executors.newCachedThreadPool();
Executors.newSingleThreadExecutor();
Executors.newWorkStealingPool();
除了最后一个以外, 每一个方法都可以将线程工厂传入进行初始化. 这几个工厂方法特性如下:
i.newScheduledThreadPool(int corePoolSize) 支持定时及周期性任务执行, 使用了 DelayQueue 队列内元素必须实现Delayed接口, 这就意味着传进去的任务必须先实现Delayed接口. 这个队列接收到任务时, 首先先入队, 只有达到了指定的延时时间, 才会执行任务.
ii.newFixedThreadPool(int nThreads) 可以初始化一个 corePoolSize 和 maximumPoolSize 都为 nThread 的线程池. 当线程池满, 又有新的线程加入时, 新线程将无条件加入到排队队列中. 这个模式可控制线程最大并发数(同时执行的线程数)
iii.newCachedThreadPool() 可以初始化一个可重复利用线程的线程池, 这样会显著提高大量短时间异步任务的情景. 60秒后使用完没被重新利用的线程将会被销毁. 线程池即使是空闲状态也并不消耗系统资源.(corePoolSize = 0, maximumPoolSize = 2^31 – 1). 这个模式下线程数无限制, 有空闲线程则复用空闲线程, 若无空闲线程则新建线程
iv.newSingleThreadExecutor() 相当于初始化 newFixedThreadPool(1) 的线程池, 单一的Worker工作, 可以确保线程有序执行. 所有任务按照指定顺序执行, 即遵循队列的入队出队规则.
v.newWorkStealingPool() 是 jdk1.8 新加入的线程池构造方法. 根据给定的并行等级, 创建一个拥有足够的线程数目的线程池. 会使用多重队列来降低冲突. 真实的线程数目或许会动态地增长和收缩. 一个工作窃取的线程池对于提交的任务不能保证是顺序执行的
workQueue
在初始化时, 其阻塞队列 workQueue 也不尽相同. 使用的 BlockingQueue 大致分为以下三种:
i.无界队列
队列大小无限制, 常用的为无界的LinkedBlockingQueue, 使用该队列做为阻塞队列时要尤其当心, 当任务耗时较长时可能会导致大量新任务在队列中堆积最终导致OOM.这个队列接收到任务的时候, 如果当前线程数小于核心线程数, 则新建线程(核心线程)处理任务; 如果当前线程数等于核心线程数, 则进入队列等待. 由于这个队列没有最大值限制, 即所有超过核心线程数的任务都将被添加到队列中, 这也就导致了maximumPoolSize的设定失效, 因为总线程数永远不会超过corePoolSize.
|——CorePool——|——ExtraPool——|——-Unbounded Queue………
|—————–MaxiumPool—————–|
ii.有界队列
常用的有两类, 一类是遵循FIFO原则的队列如ArrayBlockingQueue与有界的LinkedBlockingQueue, 另一类是优先级队列如PriorityBlockingQueue. PriorityBlockingQueue中的优先级由任务的Comparator决定.
ArrayBlockingQueue 可以限定队列的长度, 接收到任务的时候, 如果没有达到corePoolSize的值, 则新建线程(核心线程)执行任务, 如果达到了, 则入队等候, 如果队列已满, 则新建线程(非核心线程)执行任务, 又如果总线程数到了 maximumPoolSize, 并且队列也满了, 则发生错误.
使用有界队列时队列大小需和线程池大小互相配合, 线程池较小有界队列较大时可减少内存消耗, 降低cpu使用率和上下文切换, 但是可能会限制系统吞吐量.
|——CorePool——|——ExtraPool——-|—–Bounded Queue—(FIFO Queue/PB Queue)|
|——————MaxiumPool—————–|
iii.同步移交
如果不希望任务在队列中等待而是希望将任务直接移交给工作线程, 可使用SynchronousQueue作为等待队列. SynchronousQueue不是一个真正的队列, 而是一种线程之间移交的机制. 要将一个元素放入SynchronousQueue中, 必须有另一个线程正在等待接收这个元素. 只有在使用无界线程池或者有饱和策略时才建议使用该队列. 即 maximumPoolSize 一般设置为 Integer.MAX_VALUE.
|——CorePool——|——ExtraPool——……….(Unbounded)………
|—————–MaxiumPool—————–……….(Unbounded)………
例如, 在newCachedThreadPool() 中, 其核心线程池大小为0, 使用 SynchronousQueue 作为阻塞队列初始化, 所以一开始时没有线程接收加入的线程时, 会新建一个线程接收. (而不是因为corePoolSize = 0 加入缓存队列)
ThreadPoolExecutor的具体选择
根据不同特性需要选择不同参数的线程池. 以下几个可以作为考虑:
任务优先级/任务执行时间长短/任务对系统要求的瓶颈.
考虑任务优先级需要配合 PriorityBlockingQueue, 任务执行时间长短不一的任务可以交给多个线程池执行, 也可以按照时间长短的优先级进行排列.
至于对于系统资源的要求, 如果是 CPU 密集型的任务, 需要严格控制线程池的大小. 如果是 IO 密集型的任务, 则可以尽量安排线程. 还值得注意的是, 可以将一个任务按照对系统资源的要求不同划分成多个子任务, 采用多个线程池执行.